За 5 месяцев студенты научатся использовать в своих проектах решения, которые выдерживают сотни тысяч (и даже миллионы) запросов в секунду, смогут правильно оптимизировать работоспособность серверов, начнут эффективно использовать инструменты, которые уже есть в проектах. Также курс позволит актуализировать и систематизировать знания в сфере HighLoad.
Необходимые знания
- Владение одним из языков программирования при помощи которого можно написать сервер
- Навыки работы с SQL (составление запросов): в процессе обучения используется MySQL/PostgreSQL
- Навыки работы с Linux
Вступительное тестирование
Что вам даст этот курс?
Сегодня немногие веб-разработчики обладают достаточным опытом для создания отказоустойчивых и масштабируемых архитектур. И именно такие специалисты являются самыми высокооплачиваемыми и востребованными в крупных компаниях: Google, Mail.Ru Group, Yandex, Netflix и др.
В процессе обучения рассматриваются типичные и нетривиальные проблемы архитектуры веб-приложений. Преподаватели поделятся лучшими практиками и решениями этих проблем. В программу входит много полезной теории, и вся она будет обязательно закрепляться практикой в рамках самостоятельной работы и онлайн-вебинаров.
ОРУЖЕЙНАЯ В PERFECT WORLD / КАК РАБОТАЕТ? ЧТО ЭТО ТАКОЕ?
Процесс обучения
Все обучение проходит онлайн: вебинары, общение с преподавателями и вашей группой в telegram курса, сдача домашних работ и получение обратной связи от преподавателя. Вебинары идут дважды в неделю по 2 академических часа (то есть астрономических 1,5 часа). Все вебинары сохраняются и в записи в вашем личном кабинете. Домашнее задание выдается в среднем раз в 2 недели, а его выполнение занимает 3-5 часов. Мы горячо призываем заниматься такой самостоятельной работой, так как это поможет вам качественно освоить все изучаемые технологии на практике с поддержкой и обратной связью наших преподавателей.
Трудоустройство
Многие студенты еще во время прохождения первой части программы находят или меняют работу, а к концу обучения могут претендовать на повышение в должности. Мы оказываем помощь в вопросах карьеры на протяжении всего обучения и спустя полгода после его завершения.
- Получите помощь с оформлением резюме, портфолио и сопроводительного письма
- Разместите свое резюме в базе OTUS и сможете получать приглашения на собеседования от партнеров
Высоконагруженные системы
Перспективы направления
Средний уровень зарплат в Москве:
175 000 ₽ Junior+ специалист
270 000 ₽ Middle+ специалист
365 000 ₽ Senior специалист
актуальных вакансий
Работодатели курса
Формат обучения
Интерактивные вебинары
2 онлайн-трансляции по 2 ак.часа в неделю. Доступ к записям и материалам остается навсегда
Практика
Домашние задания + проектная работа, для усиления вашего портфолио и компетенций
Активное комьюнити
Общайтесь с преподавателями голосом на вебинарах, в закрытом чате Telegram и при проверке домашних заданий
Стоит ли играть в Perfect World в 2023 году? Какой сервер выбрать?
Программа
Введение в высокие нагрузки
В этом модуле студенты изучат то, что такое высокие нагрузки. Большая часть модуля будет посвящена особенностям архитектуры компьютеров и операционных систем. Студенты получат представление о главных проблемах, с которыми сталкивается архитектор систем.
Тема 1: Проблемы высоких нагрузок // ДЗ
Тема 2: Нагрузочное тестирование
Тема 3: Введение в docker. Обзор docker-compose
Тема 4: Введение в высокие нагрузки
СУБД в высоконагруженных проектах
В данном модуле студенты изучат особенности проектирования хранилищ для работы в условиях высоких нагрузок, методы их резервирования и масштабирования.
Тема 1: Индексы: структуры данных
Тема 2: Индексы: оптимизация запросов // ДЗ
Тема 3: Репликация: основы и алгоритмы
Тема 4: Репликация: виды репликации
Тема 5: Репликация: практическое применение // ДЗ
Тема 6: Кеширование // ДЗ
Тема 7: Транзакции в реляционных СУБД
Тема 8: Шардирование: основы и алгоритмы
Тема 9: Шардирование: практическое применение // ДЗ
Тема 10: Очереди и отложенное выполнение
Тема 11: Очереди и отложенное выполнение (часть 2) // ДЗ
Тема 12: In-Memory СУБД // ДЗ
Тема 13: OLAP и OLTP
Тема 14: Обзор ClickHouse
Разработка бэкенда высоконагруженных сервисов
Будут рассмотрены основные способы проектирования приложений, способных выдерживать высокие нагрузки. Рассмотрим инфраструктуру таких приложений, средства мониторинга и отладки. Поговорим о том, как не создавать точки отказа и обеспечить масштабируемость.
Тема 1: Когда нужны микросервисы, а когда монолиты
Тема 2: Паттерны декомпозиции системы на микросервисы
Тема 3: Domain Driven Design
Тема 4: Протокол HTTP (часть 1)
Тема 5: Протокол HTTP (часть 2)
Тема 6: Принципы организации микросервисов. Типы взаимодействий // ДЗ
Тема 7: Балансировка и отказоустойчивость (часть 1)
Тема 8: Балансировка и отказоустойчивость (часть 2) // ДЗ
Тема 9: Использование асинхронности обработки
Тема 10: Распределенные транзакции // ДЗ
Тема 11: Инфраструктура микросервисов
Тема 12: Системы конфигурации
Тема 13: Распределенное файловое хранилище
Тема 14: Мониторинг и алертинг // ДЗ
Тема 15: Средства описания архитектуры
Типовые архитектуры
Рассмотрим архитектуры типовых веб-проектов: новостного портала, рекламной системы, почтового сервиса, облачного хранилища и сайта знакомств. Мы разработаем универсальный алгоритм проектирования сервисов, научимся находить единые точки отказа и узкие места в сервисах.
Тема 1: System Design
Тема 2: Новостной портал
Тема 3: Рекламная система
Тема 4: Почтовый сервис
Тема 5: Облачное хранилище
Тема 6: Сайт знакомств
Итоговый проект
Необходимо разработать отказоустойчивую и масштабирую архитектуру веб-проекта. Далее разработать MVP по данной архитектуре.
Тема 1: Выбор темы и организация проектной работы
Тема 2: Консультация по проектам и домашним заданиям
Тема 3: Защита проектных работ
Также вы можете получить полную программу, чтобы убедиться, что обучение вам подходит
Выпускная работа
Заключительный месяц курса посвящен проектной работе. Его разработка нужна для окончательного закрепления знаний, которые были получены в рамках пройденных занятий.
Вы можете выбрать одну из предложенных преподавателем тем или реализовать свою идею.
Преподаватели
Руководитель курса
Никита Сапогов
Виталий Юшкевич Lead engineer Pugofka
Анатолий Бурнашев SRE expert MTS Digital
Илья Феоктистов
Константин Новаковский
Андрей Поляков
Антон Цитульский
Игорь Золотарев
Эксперты-практики делятся опытом, разбирают кейсы студентов и дают развернутый фидбэк на домашние задания
Ближайшие мероприятия
Открытый вебинар — это настоящее занятие в режиме он-лайн с преподавателем курса, которое позволяет посмотреть, как проходит процесс обучения. В ходе занятия слушатели имеют возможность задать вопросы и получить знания по реальным практическим кейсам.
Что такое индексы в БД, как они работают и зачем они нужны
Никита Сапогов
Приглашаем вас 5 октября в 20:00 мск на урок по теме «Что такое индексы в базах данных, как они работают и зачем они нужны» в рамках курса «Highload Architect». На этом уроке мы рассмотрим концепцию индексов в базах данных, узнаем, как они работают и почему они являются важной составляющей при проектировании высоконагруженных систем.
В ходе урока мы осветим следующие вопросы:
1. Значение индексов в базах данных:
— Зачем нужны индексы и как они повышают производительность запросов;
— Улучшение скорости поиска данных с помощью индексов;
— Влияние индексов на использование ресурсов системы.
2. Различные типы индексов:
— B-деревья и их применение в базах данных;
— Хэш-индексы и их особенности;
— Индексы с префиксным сжатием и другие типы индексов.
3. Процесс работы с индексами:
— Понимание процесса поиска и выбора соответствующего индекса для запроса;
— Учет затрат на поддержку индексов и их обновление при изменении данных;
— Оптимизация производительности с помощью управления индексами.
Присоединяйтесь к нашему открытому уроку, чтобы узнать больше о роли и значимости индексов в базах данных. . Читать дальше
5 октября в 17:00
Открытый вебинар
Записаться
Greenplum в высоконагруженных системах
Дмитрий Золотов
Приглашаем вас 16.10 в 20:00 мск на урок, посвященный использованию Greenplum в высоконагруженных системах. Greenplum — это мощная распределенная база данных, специально разработанная для аналитических задач. На этом уроке мы рассмотрим основные аналитические возможности Greenplum, настройку и практический пример его использования в реальной системе.
В ходе урока вы узнаете:
1. Обзор аналитических возможностей Greenplum:
— Масштабируемость и производительность Greenplum в высоконагруженных сценариях;
— Оптимизация запросов и использование партиционирования для ускорения выполнения запросов;
— Поддержка аналитических функций, оконных функций и операций над массивами данных;
— Интеграция с экосистемой инструментов для работы с большими объемами данных.
2. Настройка Greenplum для высоконагруженных систем:
— Развертывание и конфигурация Greenplum с учетом требований вашей системы;
— Управление и настройка конфигураций сегментов и репликации данных;
— Масштабирование и мониторинг Greenplum для эффективной обработки высокой нагрузки.
3. Пример с использованием Greenplum в реальной системе:
— Рассмотрение практического примера использования Greenplum для решения конкретной задачи;
— Демонстрация основных шагов и действий при работе с Greenplum в реальном сценарии;
— Практические советы и рекомендации для оптимального использования и эффективного анализа данных в Greenplum.
Присоединяйтесь к нашему открытому уроку, чтобы узнать, как использовать Greenplum в высоконагруженных системах и получить практические навыки для успешной работы с этой мощной аналитической базой данных. Добро пожаловать в мир Greenplum! . Читать дальше
16 октября в 17:00
Открытый вебинар
Записаться
Прошедшие
мероприятия
Антон Цитульский
Открытый вебинар
Распределенные транзакции в System Design
Андрей Поляков
Открытый вебинар
Индексы в PostgreSQL
Для доступа ко всем прошедшим мероприятиям необходимо пройти входное тестирование
Возможность пройти вступительное тестирование повторно появится только через 2 недели
Результаты тестирования будут отправлены вам на email, указанный при регистрации.
Тест рассчитан на 30 минут, после начала тестирования отложить тестирование не получится!
Вступительное тестирование
Корпоративное обучение для ваших сотрудников
Отус помогает развивать высокотехнологичные Команды. Почему нам удаётся это делать успешно:
- Курсы OTUS верифицированы крупными игроками ИТ-рынка и предлагают инструменты и практики, актуальные на данный момент
- Студенты работают в группах, могут получить консультации не только преподавателей, но и профессионального сообщества
- OTUS проверяет знания студентов перед стартом обучения и после его завершения
- Простой и удобный личный кабинет компании, в котором можно видеть статистику по обучению сотрудников
- Сертификат нашего выпускника за 5 лет стал гарантом качества знаний в обществе
- OTUS создал в IT более 120 курсов по 7 направлениям, линейка которых расширяется по 40-50 курсов в год
Получить коммерческое предложение
Отзывы
Евгений Ролдухин
Здорово, что наконец-то появился полноценный курс по построению Highload систем! До этого альтернативой было только самостоятельного изучение и сбор информации с конференций и чтение статей. Что было хорошо: Курс в целом оставил приятное впечатление, однозначно выросло понимание и возможный инструментарий для работы.
Например, лямбда-архитектура, Tarantool, cARP были для меня абсолютно неизвестными вещами. Полезными были разборы кейсов реальной архитектуры. Что было плохо: — Крайне долгая проверка домашних заданий.. и частые переносы занятий, это крайне демотивирует. — Дублирование: спикеры были разные и было несколько раз (больше 3х), что они начали повторять в своей лекции уже пройденный материал.
Что можно сделать лучше: — Структура курса: все не объять, но ожидал много литературы на домашнее чтение + сейчас кажется, что курс стоит дополнить, как минимум, бинарными хранилищами и информационным поиском. При этом темы «микросервисы», «очереди», «http» вызывали скуку, лучше отдать это на самостоятельное изучение и копать в глубину, тем более рассказы были вполне на уровне, что можно посмотреть на ютубе. — Подписка на новые
Источник: otus.ru
УСПЕШНЫЙ ВЫЗОВ НА БОЙ ПВ ДЛЯ ЧЕГО
Perfect World — это многопользовательская онлайн-игра, где многие игроки проводят большую часть своего времени, чтобы развивать своих персонажей и участвовать в зрелищных боях PvP.
Вызов на бой ПВ — это один из самых важных аспектов игры, поскольку он предоставляет возможность сражаться с другими игроками и показать свои навыки. Однако, чтобы иметь уверенность в том, что ваш вызов на бой будет успешным, важно убедиться, что ваш персонаж имеет достаточный уровень опыта и снаряжения для битвы.
Один из способов повысить свои шансы на победу в бою ПВ — это тесно сотрудничать с другими игроками, чтобы создать мощную команду. Командная работа, включая стратегическое планирование и координацию усилий в бою, может дать вам преимущество перед вашими противниками.
Наконец, для успешного вызова на бой ПВ также важно выбирать правильное время и место для сражения. Некоторые области могут предоставлять бонусы или преимущества, которые вы можете использовать в свою пользу, поэтому будьте внимательны при выборе места для битвы.
Как выполнить достижение Боевой хирург в pubg mobile
ГАЙД ГБП ФАСТ СТРАЖЕМ + ФРАГМЕНТ
ЗАТОЧКА ШАРАМИ ЛУЧНИКА В ПВ! COMEBACK 1.4.6 X / PERFECT WORLD 2023
Скрытый квест на Адское пламя: бой огней. Perfect World Mobile
Perfect World mobile:Задание
Типы людей во время пвп в пв
Скрытый квест Perfect World Mobile
КРАХ ОБЗОР ГЕРОЯ — ГАЙД ДЛЯ НОВИЧКОВ — Watcher of Realms
Источник: pwdata.ru
Что такое и зачем нужны 1st, 2nd и 3rd party data
Разберём в статье, что такое 1st, 2nd и 3rd party data, как использовать их в маркетинге, как собирать информацию о клиентах без нарушения конфиденциальности.
Данные — это основа маркетинга. 54% маркетологов говорят, что успех рекламных кампаний зависит от количества и полноты данных. Без нужной информации маркетинг движется вслепую и теряет деньги, а бизнес, который персонализирует общение с клиентом на основе данных, получает ROI в 5–8 раз выше. Поэтому компании переходят на data-driven подход.
Сбор информации из нескольких каналов даёт обзор аудитории на 360°, персонализацию и масштабирование бизнеса, также предсказание поведения пользователей. Данные об аудитории не равноценные и нужны для разных задач. По способу получения и уникальности выделяют 1st, 2nd и 3rd party data.
Что такое 1st party data
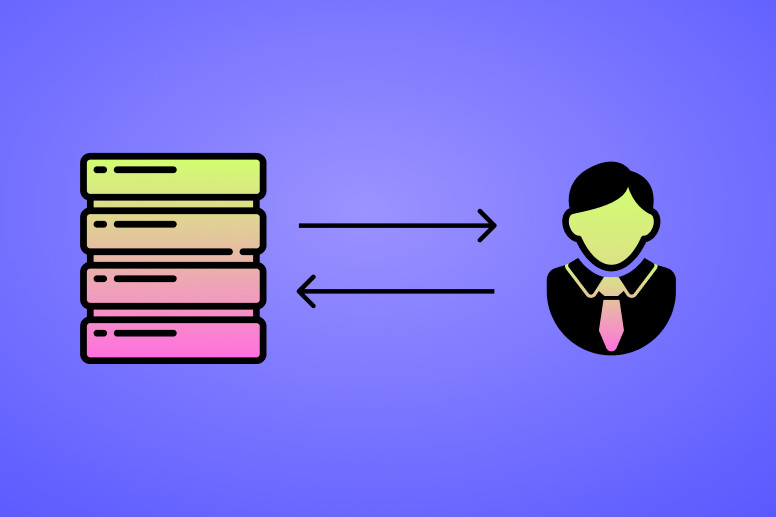
1st party data — данные, которые компании получают от клиентов напрямую через регистрации, пиксели и cookies на сайте, CRM и другие сервисы. Ограничений на сбор информации нет, кроме разрешений пользователей. Клиент может отказаться предоставлять данные, хотя оставить имя, номер телефона или почту обычно не проблема.
- поведение и время на сайтах и в приложениях;
- результаты рассылок по email и SMS (open rate, клики);
- контактные данные: почта, номер телефона;
- информация о заказах клиентов;
- обратная связь;
- демографические данные;
- результаты опросов пользователей;
- поведение в соцсетях;
- интересы.
Плюсы first party data — бесплатность, достоверность, полное владение, потому что у конкурентов нет доступа к информации компании. Минус — 1st party data недостаточны для масштабирования.
- Изучение глубинных потребностей клиента и предложение продукта, который точно купят.
- Персонализация предложений и контента для клиента.
- Запуск рекламы и кампании для ретаргетинга.
- Предсказание поведения клиента.
Пример. Клиент покупал в интернет-магазине футболки марки N. Через полгода он заходил на сайт и добавлял такие же в корзину. Из этого мы делаем вывод, что возможна покупка в будущем. Компания «предугадывает» действия и подталкивает клиента: предлагает специальные условия, скидку, напоминает о товаре в рассылке.
Что такое 2nd party data
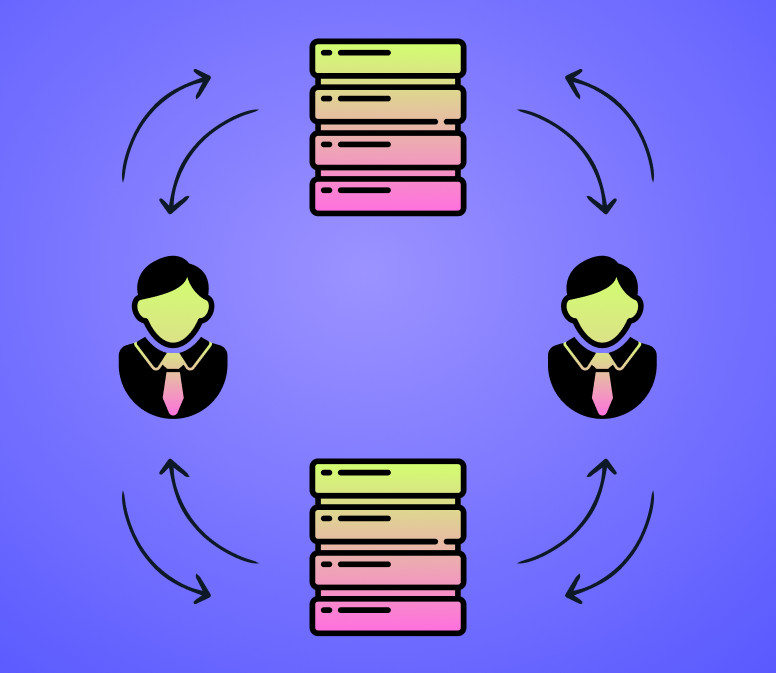
2nd party data — это 1st party data, которые собрала другая компания из своих источников. Second party data покупают у партнёров или сторонних компаний с релевантной аудиторией.
- Масштабирование бизнеса. Только с 1st party data освоить новые рынки трудно. Здесь есть риски ошибок и неправильных действий. Бизнес не знает аудиторию, с которой собирается работать. Со сторонней информацией проще запустить первые рекламные кампании.
- Дополнение первичных данных. 2nd party data укажут на проблемы в воронке продаж.
- Отслеживание трендов. Вывод только по собственным данным — узкий обзор, сторонняя информация даёт больше объективности.
- Укрепление партнёрства. Обмениваться данными взаимно — повышать доверие между бизнесами.
- Неожиданные идеи для креативных компаний.
Пример. Турагентство покупает 2nd party data у интернет-магазина чемоданов и сумок для путешествий. По данным партнёра 30% клиентов магазина покупают сумки для перевозки собак. Агентство запускает новый продукт и рекламную кампанию для путешественников с животными.
Недостаток 2nd party data — нельзя назвать данные на 100% точными и релевантными. Неизвестно, как и когда собирали информацию. Покупка зависит от доверия к продавцу и чужим методам сбора данных.
Что такое 3rd party data
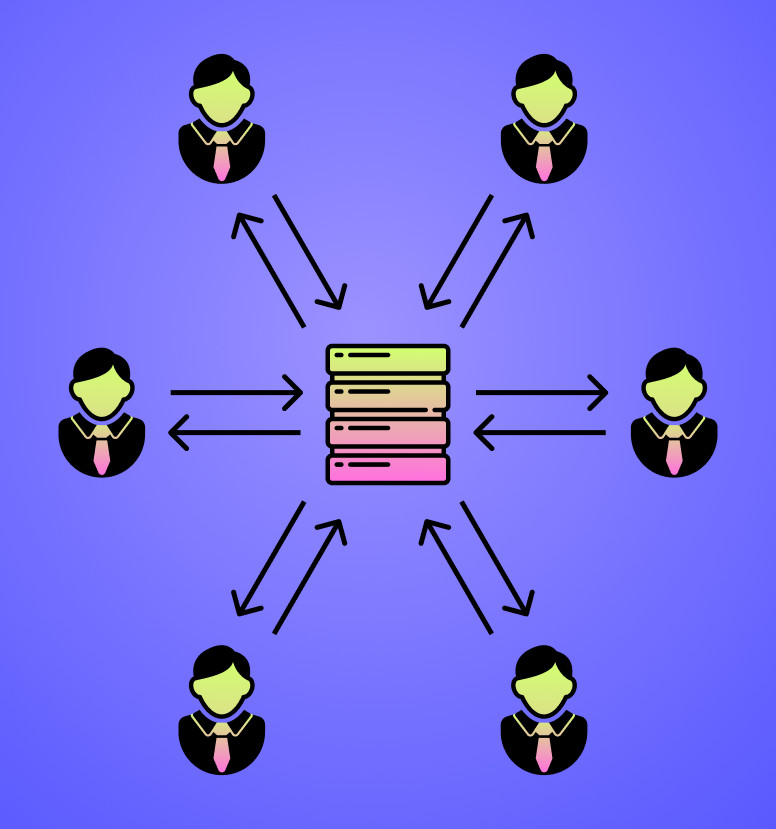
3rd party data — данные из нескольких источников, которые собирают агрегаторы. Включают перекупленные 2st party data компаний и/или собственные собранные данные через опросы, исследования, интервью и автоматические методы. Примеры агрегаторов: Nielsen, eXelate, Acxiom, OnAudience, BlueKai, Oracle Data Cloud, Peer39, сервисы Google, платёжные системы и другие. Социальные сети — тоже агрегаторы данных, которые продают готовые аудитории для рекламы. Продавцы 3rd party data собирают информацию и сегментируют её по категориям для поиска по индустриям, по интересам и так далее.
- гендерные данные;
- интересы;
- уровень дохода;
- география;
- профессии.
- Расширять 1st party data и закрывать проблемы в изучении аудитории и повышать персонализацию.
- Изучать и получать идеи для развития бизнеса. 3rd party data — это больший охват аудитории, чем данные первого и второго уровня.
- Запускать таргетированную рекламу на потенциальную аудиторию.
- Отслеживать глобальные тренды, а не местечковых.
Плюсы — third party data часто собирают автоматически, так что это актуальная информация для быстрой смены стратегии маркетинга. Минусы — нельзя проверить достоверность данных, такая же информация доступна конкурентам.
Важно работать со всеми типами данных и дополнять одни другими.
Вернёмся к примеру с бизнесом по продаже женской одежды для фитнеса (см. выше), который решил расширить ассортимент с мужской линией. 2nd party data — основа для первой кампании, но охват аудитории у продавца данных оказался недостаточный. Для дополнения информации о клиентах и расширения аудитории компания покупает 3rd party data.
Сбор трёх типов данных в одну систему предоставляет полный обзор пользователя. Больше знаем о клиенте — проще «дотянуться» и быстрее продать.
Как собирать данные
В мире тенденция к усилению приватности персональной информации. Сбор ограничивает законодательство и сами компании, которые собирают данные.
GDPR (General Data Protection Regulation) — регламент, который защищает персональные данные пользователей Евросоюза и действует для компаний, которые работают с гражданами этих территорий. Человек может запросить личные данные, скорректировать и даже потребовать удалить, отозвать разрешение на обработку.
В России ФЗ «О персональных данных» запрещает раскрывать данные пользователей третьим лицам без согласия.
Google ограничивает Cookies для 3d party data в браузере Chrome. Компания планирует отказаться от сторонних cookies в течение 2022 года для усиления конфиденциальности пользователей в сети. Такой подход — проблема для отслеживания пути клиента к конверсии и интересов. С анализом данных внутри кабинетов ничего не изменится, а для сквозной аналитики узнать путь клиента через кросс-девайсы станет сложно или невозможно.
Apple для браузера Safari (от 13.1) ограничивает сторонние cookies Intelligent Tracking Prevention (ITP). Браузер запрещает сбор данных сторонних сервисов. IOS 14.5 теперь запрашивает подтверждение для сбора информации через IDFA (The Identifier for Advertisers — идентификатор для рекламы). Если пользователь отказывается, снижается точность данных. Apple предлагают альтернативу, заключающуюся в обезличенных агрегированных данных, но закрыть все потребности маркетинга такой информацией не получится.
Правила сбора данных
- Поставить в приоритет 1st party data, собирать 2nd party data, чтобы строить собственную систему данных и меньше зависеть от сторонних.
- Уведомлять пользователей о сборе данных и спрашивать разрешение на обработку. Нельзя считать целевой аудиторией людей, чьи данные собираются тайно.
- Следить за законодательством по защите данных пользователей и правилами игроков на рынке информации.
Резюме
Маркетинг без данных означает работу вслепую, но не все типы данных приносят одинаковую пользу. Различают 1st, 2nd и 3rd party data. First party data — прямая информация от пользователей. Second party data — это 1st party data, которые компании выкупают у партнёров и бизнесов с похожей целевой аудиторией. Third party data — данные агрегаторов, которые выкупают информацию у компаний или собирают самостоятельно.
1st party data достоверные и простые в сборе, но не подходят для масштабирования. 2nd party data расширяют обзор аудитории для бизнеса, но проверить их достоверность сложно. 3rd party data — масштабные, но их достоверность проверить нельзя. Также third party data доступны конкурентам.
Регламенты агрегаторов данных и государственные законы тормозят сбор информации. Компании должны следить за изменениями, создавать собственные системы сбора и хранения данных, чтобы не зависеть от сторонних поставщиков.
Источник: spark.ru